/proje detayları
World Happiness Üzerine Applied Bayesian Analysis
GDP, social support, health ve regional structure kullanarak country-level happiness'i açıklamak için brms ile Bayesian regression ve hierarchical model'ler kurdum.

Bu Applied Bayesian Analysis projesi, World Happiness Report 2024 veri setini kullanarak ülke düzeyindeki happiness score'ları modellemeye odaklanıyor. Ana predictor'lar GDP, social support ve healthy life expectancy; continent ve region bilgisi ise hierarchical structure kurmak için kullanıldı.
Analiz R ve brms ile yürütüldü. brms, Prof. Dr. Paul Bürkner tarafından geliştirilen bir Bayesian regression modeling package'i. Bu sayede çalışma, expressive model formula'ları, Stan-backed sampling, posterior check'ler ve uncertainty-aware interpretation içeren modern Bayesian workflow'un tam içinde konumlanıyor.
Önce data cleaning, missing-value handling, correlation checks, region mapping ve exploratory visualization adımlarını tamamladım. Ardından dört modeli sırayla kurdum: pooled Gaussian regression, region bazlı varying-intercept model, GDP için region bazlı varying-slope model ve non-linear health effects için spline-based model.
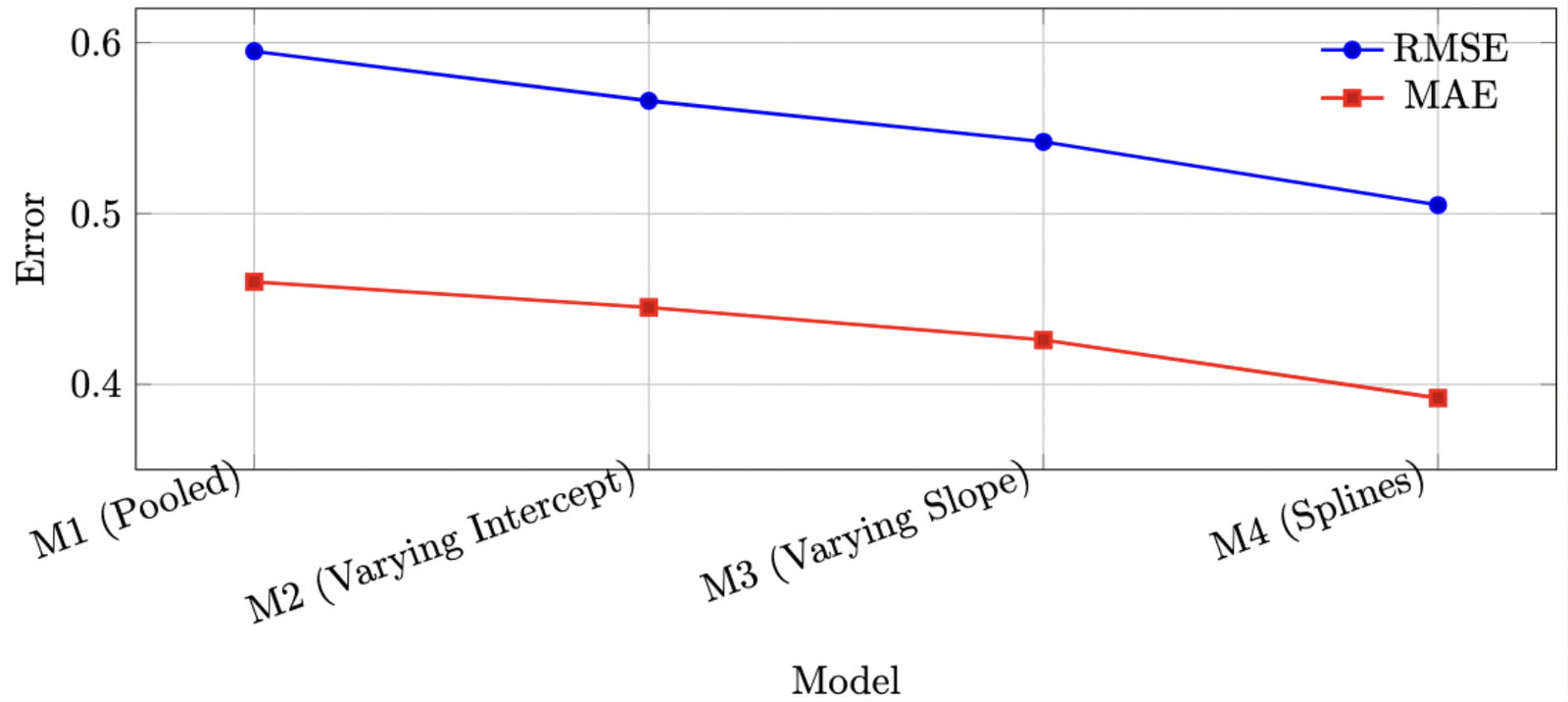
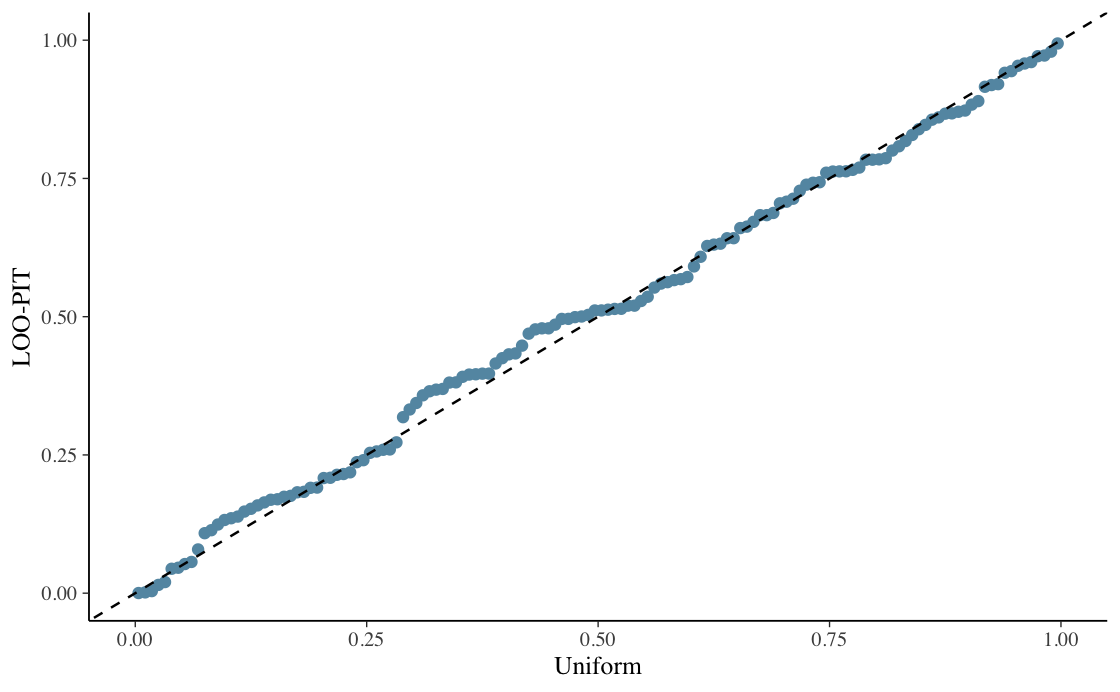
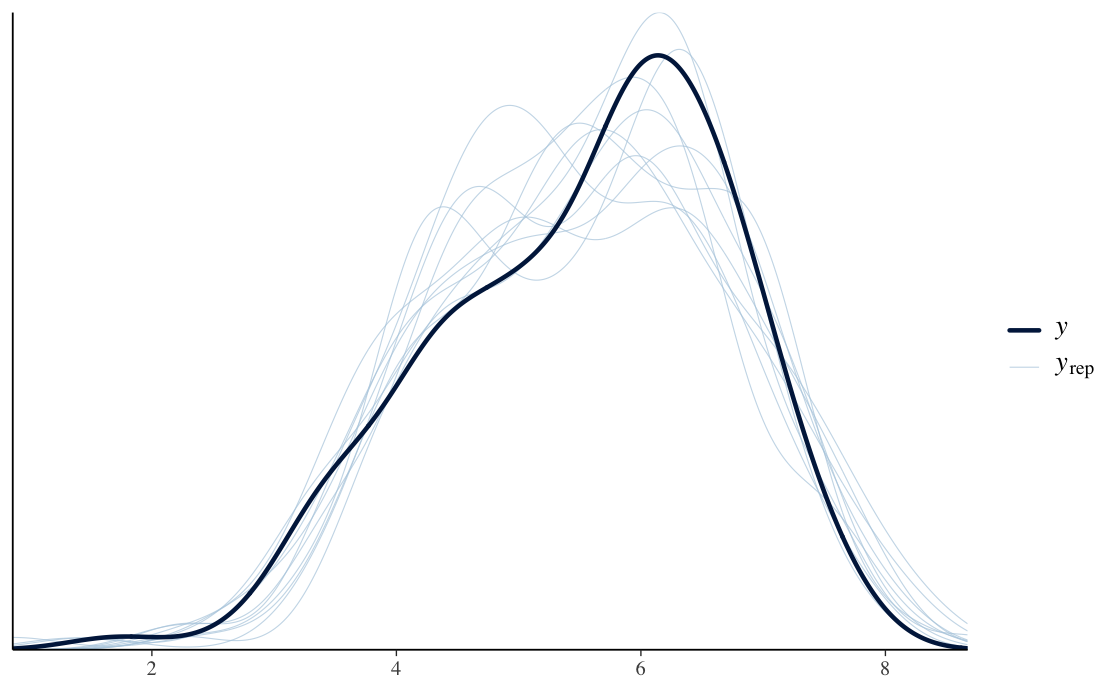
Projenin önemli kısmı yalnızca modelleri fit etmek değil, aynı zamanda dikkatli biçimde kontrol etmekti. Trace plot, posterior summary, posterior predictive check, conditional effect, LOO-PIT style check, Bayesian R2, RMSE ve MAE kullanarak model davranışını ve predictive quality'yi karşılaştırdım.
Öne çıkanlar
- World Happiness Report 2024 verisini 143 ülkeden 140 complete country observation'a temizledim.
- Hierarchical Bayesian modeling için ülkeleri region/continent seviyesine map ettim.
- brms ve Stan kullanarak pooled, varying-intercept, varying-slope ve spline-based model'ler fit ettim.
- Coefficient'ler için normal prior, group-level standard deviation için exponential prior gibi weakly informative prior'lar kullandım.
- Model'leri posterior predictive check, trace diagnostic, conditional effect, Bayesian R2, RMSE ve MAE ile değerlendirdim.
- Uncertainty'yi tek bir point estimate arkasına saklamak yerine model output'unun temel parçası olarak ele aldım.
Model Formülleri
y_i ~ Normal(β0 + β1 * GDP_i + β2 * Support_i + β3 * Health_i, σ) Tüm ülkeler için ortak katsayılar kullanan temel Gaussian regresyon modeli.
y_i ~ Normal(α_region[i] + β1 * GDP_i + β2 * Support_i + β3 * Health_i, σ), α_r ~ Normal(μ_α, τ_α) Her bölgenin farklı bir başlangıç mutluluk düzeyine sahip olmasına izin verir.
y_i ~ Normal(α_region[i] + β1,region[i] * GDP_i + β2 * Support_i + β3 * Health_i, σ), β1,r ~ Normal(μ_β1, τ_β1) GDP etkisinin bölgelere göre değişmesine izin verir.
y_i ~ Normal(α_region[i] + β1,region[i] * GDP_i + β2 * Support_i + s(Health_i), σ) Hiyerarşik yapıyı korurken health değişkeni için düzgün, doğrusal olmayan bir etki ekler.
Figürler