/Project Details
Gini Index Decision Tree Classification
A reproducible machine-learning project that explains how Gini impurity drives threshold selection and decision-tree classification.
This project focuses on explaining one of the fundamental split criteria behind decision trees: Gini impurity. Rather than presenting the model as a black box, the goal is to show step by step, and as intuitively as possible, how Gini impurity works.
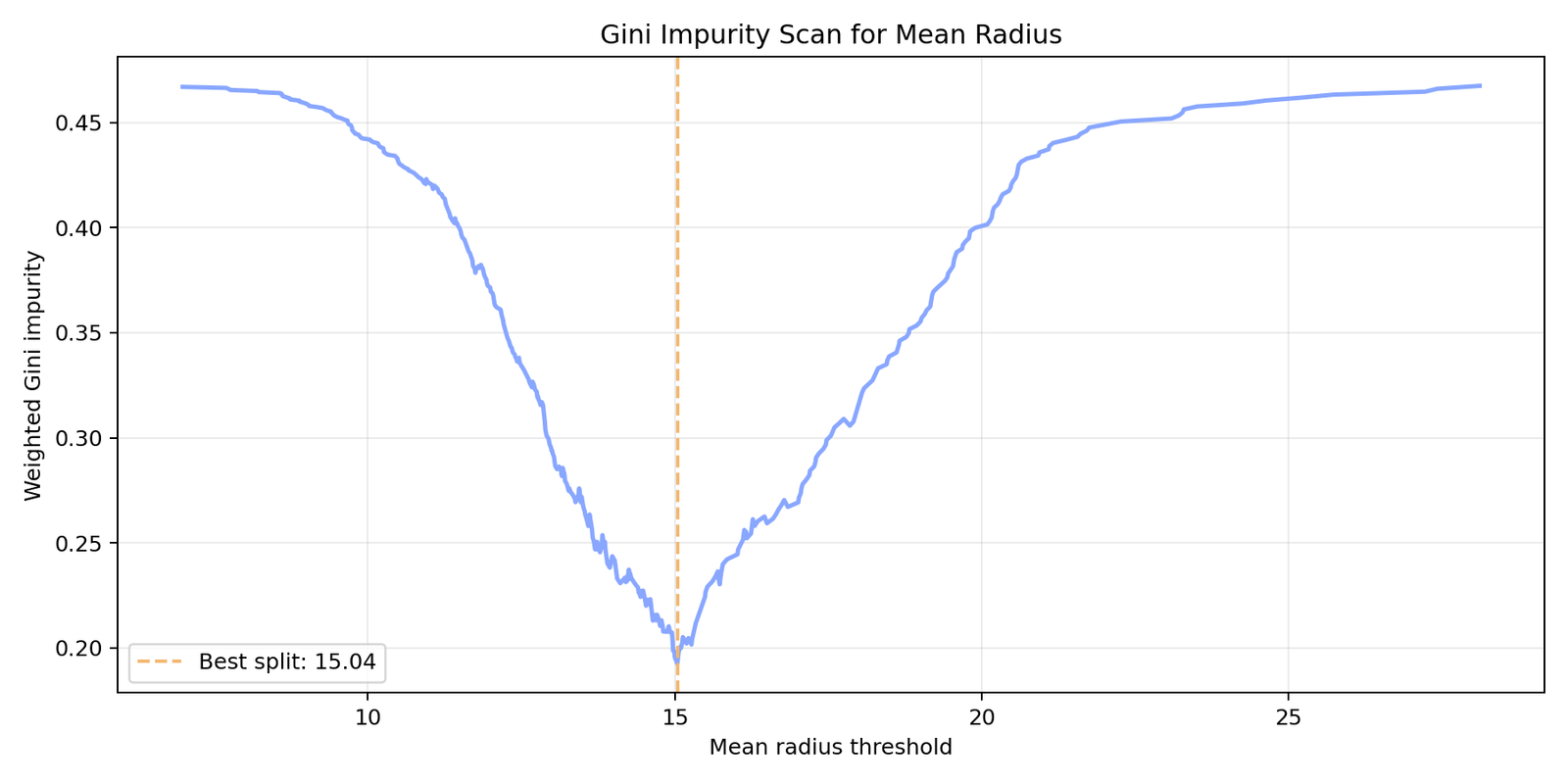
For that purpose, Gini impurity is first computed manually and candidate threshold values are systematically scanned for a single feature. This makes it clear which threshold provides the best data separation.
The reproducible version uses the Breast Cancer Wisconsin dataset from scikit-learn, which allows the full workflow to run without external downloads or private CSV files.
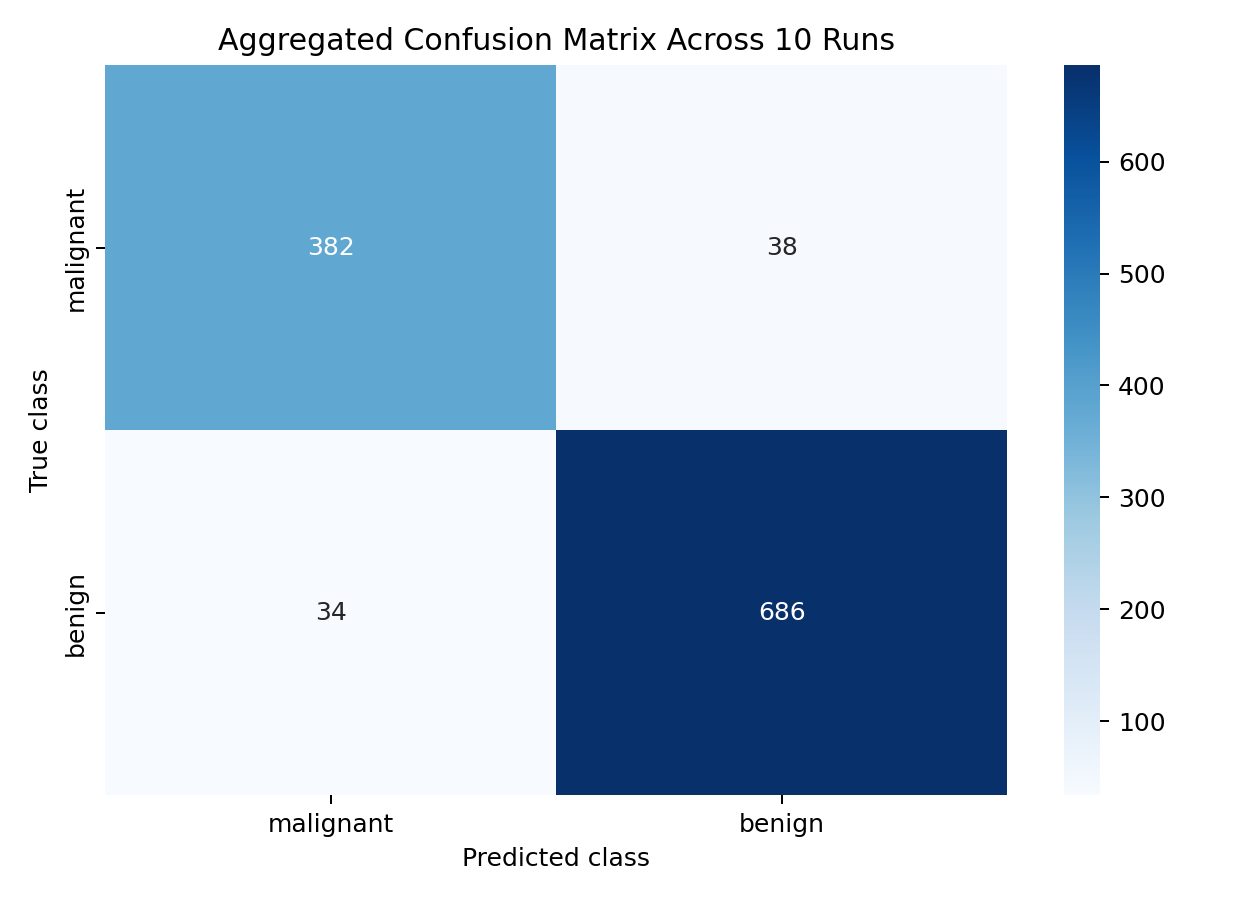
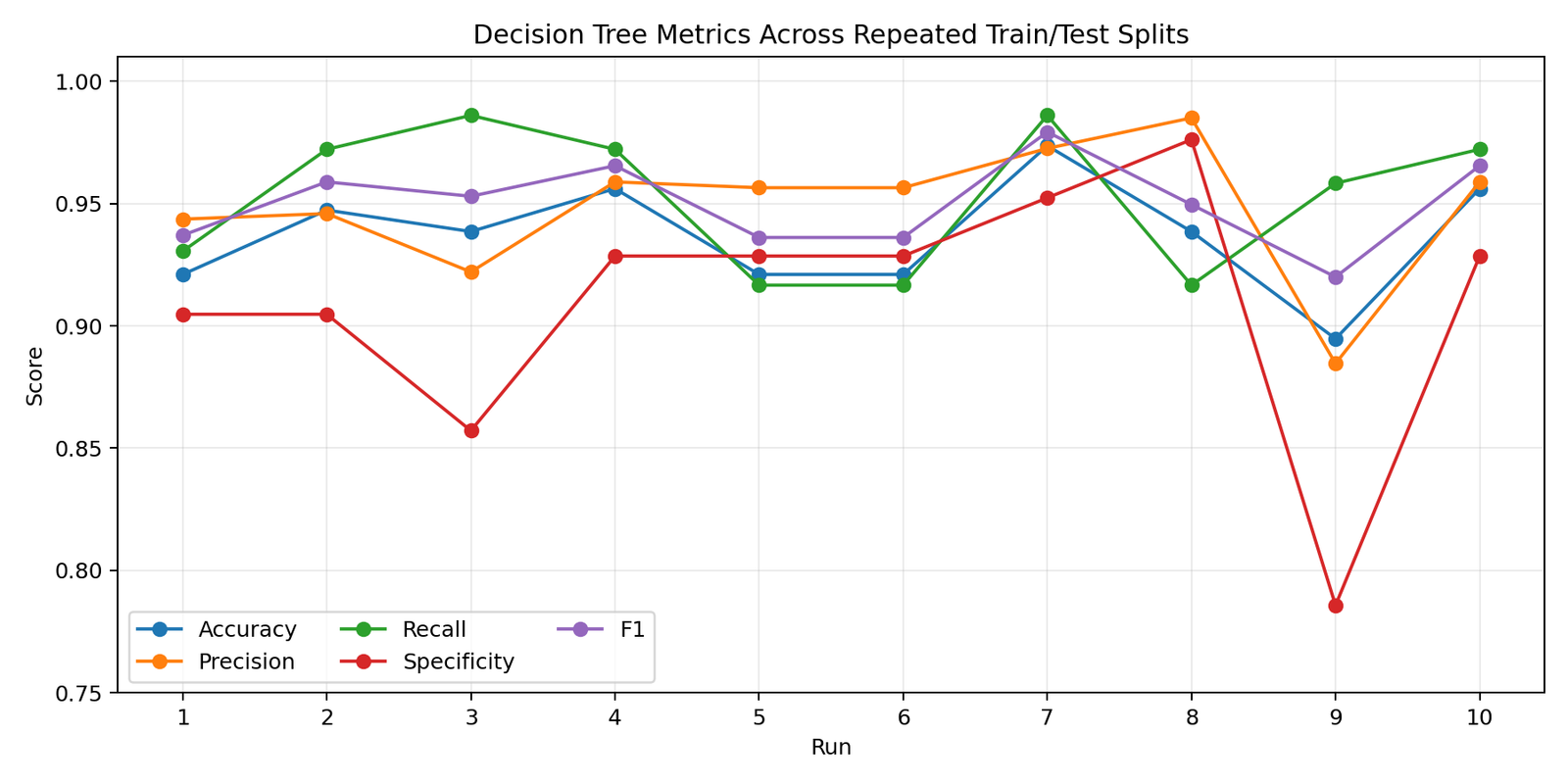
After the threshold scan, a Gini-based DecisionTreeClassifier is trained across 10 stratified train/test splits. Model performance is then evaluated comprehensively with accuracy, precision, recall, specificity, F1 score, and an aggregated confusion matrix.
Highlights
- Implemented Gini impurity and weighted threshold scoring from scratch.
- Visualized and analyzed the best threshold for the mean-radius feature.
- Trained a max-depth-3 decision tree with the Gini criterion across 10 repeated data splits.
- Reached mean accuracy around 0.94 and mean F1 around 0.95 in the reproducible demo.
- Structured the project as a transparent ML example focused on interpretability rather than black-box performance.
Figures